Pegelstandmesser mit Kubernetes, OCR und Google Assistant
Es gibt da ein Problem: Wenn ich joggen gehe, dann mache ich das am Ufer eines kleinen Flusses, der an meiner Wohnung vorbeifließt. Da ist es schön, entspannend und vor allem leicht zu erreichen. Nach ein paar hundert Metern geht es bergab, und da liegt dann das Problem: Ab einem bestimmten Wasserstand kommt man hier ohne Badehose nicht mehr durch und ich muss wieder umkehren (die Belohnungspizza esse ich natürlich trotzdem). Berufsbedingt habe ich mir nun die Frage gestellt, ob das Problem nicht technisch elegant gelöst werden kann.
IDEE UND DAS ZIEL
Ich würde am liebsten mein Handy bzw. Google Assistant (Also auch Google Home) direkt fragen können, ob ich eigentlich gerade joggen gehen kann, oder nicht. Entscheidend dafür ist eigentlich nur ein irgendwo in der Nähe abgerufener Pegelstand des Flusses. Klar - ein kurzer Blick darauf würde reichen, aber mir geht es primär um die Tüftelei und die Frage, ob ich diese Aufgabe mit den Mitteln moderner Digitalisierung umgesetzt bekomme.
Ich möchte in diesem Artikel einen Überblick darüber geben, was mit “Enterprise”-Tools wie Rancher2, Kubernetes, Docker, DialogFlow und OCR auch im kleinen Freizeit-Rahmen schnell und einfach umgesetzt werden kann. Er ist nicht als Schritt-für-Schritt-Anleitung zu verstehen, um etwas vergleichbares nachzubauen. Das würde den Rahmen des Artikels sprengen und es gibt zu allen unten aufgeführten Themen sehr umfangreiche Dokumentation im Netz.
RECHERCHE, MATERIALSAMMLUNG UND UMSETZUNG
Nach kurzer Suche im Netz wurde ich fündig: Eine behördliche Website veröffentlicht im 15-Minuten-Takt den Pegelstand einer Messstation nur wenige Kilometer entfernt. Neben Pegelstands-Grafiken gibt es glücklicherweise auch eine reine Zahlentabelle, die allerdings nur als Bilddatei zur Verfügung steht.
Nach weiteren Recherchen zum Thema und dem Vorwissen aus der täglichen Arbeit mit Rancher, Kubernetes und Docker bin ich letztendlich auf folgende Liste benötigter Tools gekommen und habe mit der Umsetzung angefangen:
DOCKER NR. 1
Ein Script, das den aktuellen Pegelstand herausfindet und anhand dessen die Entscheidung fällen kann, ob man joggen gehen kann, oder nicht:
-
Eine Variable, die definiert ab welchem Wasserstand der Weg überflutet ist. Aus der Erfahrung heraus habe ich hier mal ca. 85cm angenommen.
-
wget, um die Pegelstands-Tabellen-Grafik der Website herunter zu laden. Offenbar ändert sich der Dateiname über Zeit nicht und die Grafik wird im 15-Minuten-Takt einfach überschrieben.
-
tesseract-ocr - Eine OpenSource OCR-Software, um aus dem Bild wieder eine reine Text-Tabelle aus Datumsfeld und Pegelstand in Zentimetern zu generieren. Die Software ist denkbar einfach zu verwenden: Bild angeben, Text herausbekommen. Es gibt einige Optionen und Parameter mit denen ich experimentiert habe, aber das beste Ergebnis ist bereits mit den default-Einstellungen erreichbar. Lediglich das Paket für die Unterstützung der deutschen Sprache sollte man noch installieren, wenn man keine reinen Wertetabellen erkennen lassen möchte. Ein interessantes Learning gab es hier allerdings: Meine Tests mit tesseract habe ich lokal unter Ubuntu 18.04 durchgeführt. Ich wollte für meinen Docker zunächst alpine Linux verwenden, um das resultierende Docker-Image so klein wie möglich zu halten. Daraufhin bekam ich keinerlei Messwerte mehr aus meinem Script zurückgemeldet. Ein Blick unter die Haube zeigte dann, dass die tesseract-Version, die in Alpine als Package integriert ist, erheblich schlechtere Erkennungsergebnisse bei gleichem Input liefert. Ob es sich einfach um eine ältere tesseract-Version handelte oder im tesseract von Alpine andere Erkennungsmodelle verwendet werden habe ich nicht weiter untersucht. Ich habe stattdessen auf Ubuntu 18.04 als Dockerbasis umgestellt.
-
grep, awk, cut - Diverse Shell-Tools, um das OCR-Ergebnis gegen eine restriktive RegularExpression zu filtern, da nicht alle Zeilen immer zuverlässig erkannt werden. Aus dem neuesten Pegelstands-Wert und dem Datum ir dann ein eine vom Google Assistant verarbeitbare Antwort im JSON-Format erstellt. Das JSON soll in eine Datei geschrieben werden, da der OCR-Prozess wegen des großen Bildes doch einige Sekunden benötigt und das Ergebnis jederzeit asynchron abgerufen werden können soll.
-
Dieses Script soll als CronJob laufen, also periodisch ebenfalls alle 15 Minuten aufgerufen werden und die genannte JSON-Datei erstellen.
-
docker - dieses Script soll in einem eigenen Docker ausgeführt werden, damit die o.g. Pakete gekapselt sind.
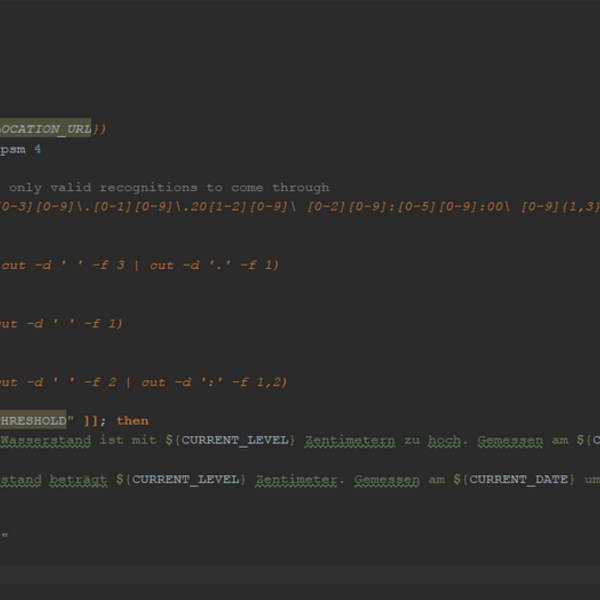
Das Script - die olivgrün hinterlegten Variablen übergebe ich aus der Kubernetes-Umgebung heraus.
DOCKER NR. 2
Ein Go-Script meines Kollegen Matthias, das einen Webserver bereitstellt und bei einem GET-Aufruf ein vorher via Environment-Variable definiertes Shell-Kommando ausführt und das Ergebnis ausgibt. Hier also einfach ein “cat /mnt/pegelstand/pegelstand.json”. So spare ich mir einen nginx oder apache. Das script steht bereits als binary in einem Docker zur Verfügung. Der soll allerdings nicht als CronJob, sondern als stetig verfügbarer Webserver-Service ausgeführt werden.
RANCHER2 / KUBERNETES
Ich habe bereits einige von Rancher2 verwaltete Kubernetes-Cluster zur Verfügung stehen. Es ist also naheliegend die beiden oben genannten Docker auf einem dieser Cluster zu deployen: Den Ersten als CronJob, der alle 15 Minuten ausgeführt wird und den Zweiten als normales Deployment. CronJobs und normale Services im gleichen Pod zu halten ist von Kubernetes nicht vorgesehen - ich kann daher nicht auf ein Ephemeral emptyDir als Volume zurückgreifen, sondern muss ein normales Verzeichnis vom Host als shared Volume verwenden.
Nachdem das lief, habe ich unter Rancher2 einen passenden Ingress erstellt, damit externe Zugriffe auf das JSON-File möglich werden. Dazu gehört auch die Installation des Certbot-Kubernetes-Charts, um letsencrypt-TLS-Zertifikate erhalten zu können.
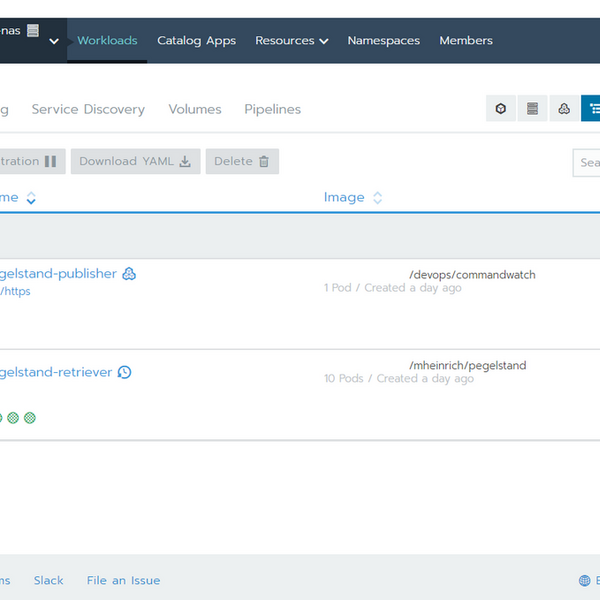
Screenshot des Projekts in Rancher2, der den Kubernetes-Cluster steuert.
GOOGLE ASSISTANT INTEGRATION MIT DIALOGFLOW
Mit diesem Teil der Lösung kannte ich mich bis dato am wenigsten bzw. gar nicht aus - höchste Zeit also, sich hier mal etwas einzuarbeiten: Bei meinen Recherchen zum Thema GoogleAssistant-Integration bin ich immer wieder über “api.io” gestolpert, was inzwischen “DialogFlow” heißt. Das Unternehmen wurde von Google aufgekauft, gehört inzwischen zum Konzern, ist sehr tief mit Googles API Console verwoben und ist eine Art Baukasten, um Dialogprozesse zwischen dem Nutzer und Google Assistant zu modellieren.
Nach dem Anmelden bei DialogFlow, was soweit ich sehen konnte auch ausschließlich über das Google-Konto erfolgt, landet man direkt in einer gut strukturierten Oberfläche in der man seinen ersten Dialog erstellen kann.
Ab diesem Zeitpunkt gibt es zahlreiche Ein- und Aussprungpunkte zwischen der DialogFlow-Oberfläche und der Google Cloud bzw. Google API Console und dem Assistant-Simulator. Ich bin noch nicht tief genug in das System eingestiegen um einschätzen zu können, ob ich die gewünschte Lösung nicht auch mit Google-Bordmitteln ohne Dialogflow hätte realisieren können, es hat den Prozess beim ersten Mal aber erheblich vereinfacht - zumindest scheint es mir aktuell so.
Das Ergebnis sieht dabei so aus, dass man den Google Assistant zunächst dazu bringen muss in den richtigen Dialog einzusteigen - so, als wenn man eine App startet. Erst danach kann man konkrete Fragen stellen, auf deren Antwort man Einfluss hat. Mir ging es nun darum meine eigene Antwort aus dem im Netz zur Verfügung gestellten JSON vorlesen zu lassen. Durch das hinzufügen eines Fulfillment-Objekts zu meinem Dialog, dem ich wiederum mein JSON-File als Webhook-URL zuweisen kann ging das ganze dann auch wie gewünscht.
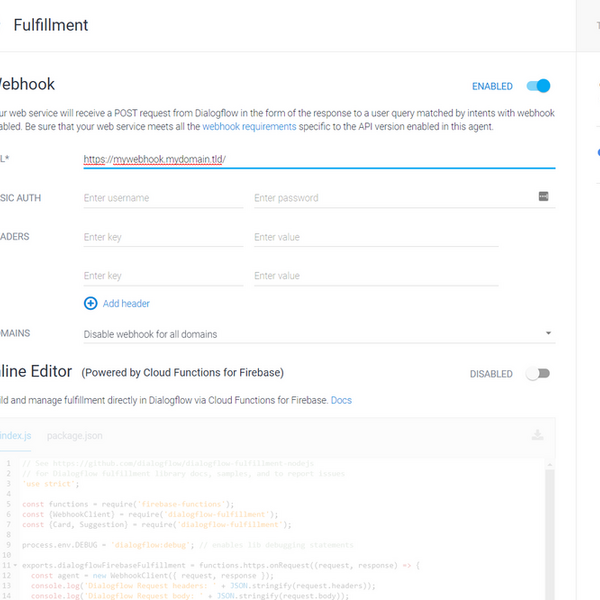
So sieht das ganze auf DialogFlow aus.
FAZIT
Es klappt! \o/ Ich kann meinem Google Assistant jetzt ansprechen mit “Hey Google, starte Pegelstand” (Das muss leider sein) und danach: “Kann ich heute joggen gehen?”. Daraufhin erhalte ich aktuell die Antwort: “Joggen ist möglich, der Wasserstand beträgt xy Zentimeter. Gemessen am soundsovielten etc.”. Das ganze war in ein paar Stunden erledigt, was für die verwendeten Tools und die Tatsache, dass ich mich mit dem Google Assistant vorher nur aus Anwendersicht auseinandergesetzt habe, eine positive Überraschung war.
Videobeweis
NACHTRAG
Ich habe in der Zwischenzeit noch ein paar Kleinigkeiten verbessert, die die Leistung und die Erkennungsqualität verbessert haben:
- In der ersten Version habe ich tesseract mit der Sprachbibliothek für Deutsch laufen lassen, auch wenn das für die Erkennung der reinen Zahlentabellen natürlich unnötig ist. Beim Testen habe ich dann festgestellt, dass die Erkennungsrate bei gleichem Input ohne das Deutsch-Wörterbuch erheblich besser ist. Ich kann nur spekulieren, warum das so ist, aber die Ergebnisse sind eindeutig. Deswegen läuft das System jetzt nur noch mit dem reinen tesseract Basissystem ohne Angabe der Sprache.
- Da ich nur die erste (erkannte) Zeile des relativ großen Bildes (Es ist eine sehr lange Tabelle) verwende ist es unnötig, die gesamte Tabelle per OCR zu verarbeiten. Ich habe daher noch imagemagick im Docker installiert, um das Bild zuzuschneiden. Dadurch ist der gesamte Prozess auf 2-3 Sekunden Gesamtlaufzeit optimiert worden. Damit könnte man jetzt ggf. auch eine synchrone Abfrage ermöglichen und den Cronjob dadurch einsparen.